The Roper Center’s comprehensive Data Curation Program ensures that the largest collection of polling data in the world will be preserved and made accessible for the long term. Data curation at the Roper Center encompasses all activities that are required to ensure the utility and authenticity of public opinion data, maintain its accessibility, and mitigate and/or reverse the effects of hardware and software obsolescence and media decay. Our staff is experienced in data processing and is dedicated to adding value to archived data by enhancing them with meaningful information, making them complete, usable, and independently understandable for future researchers.
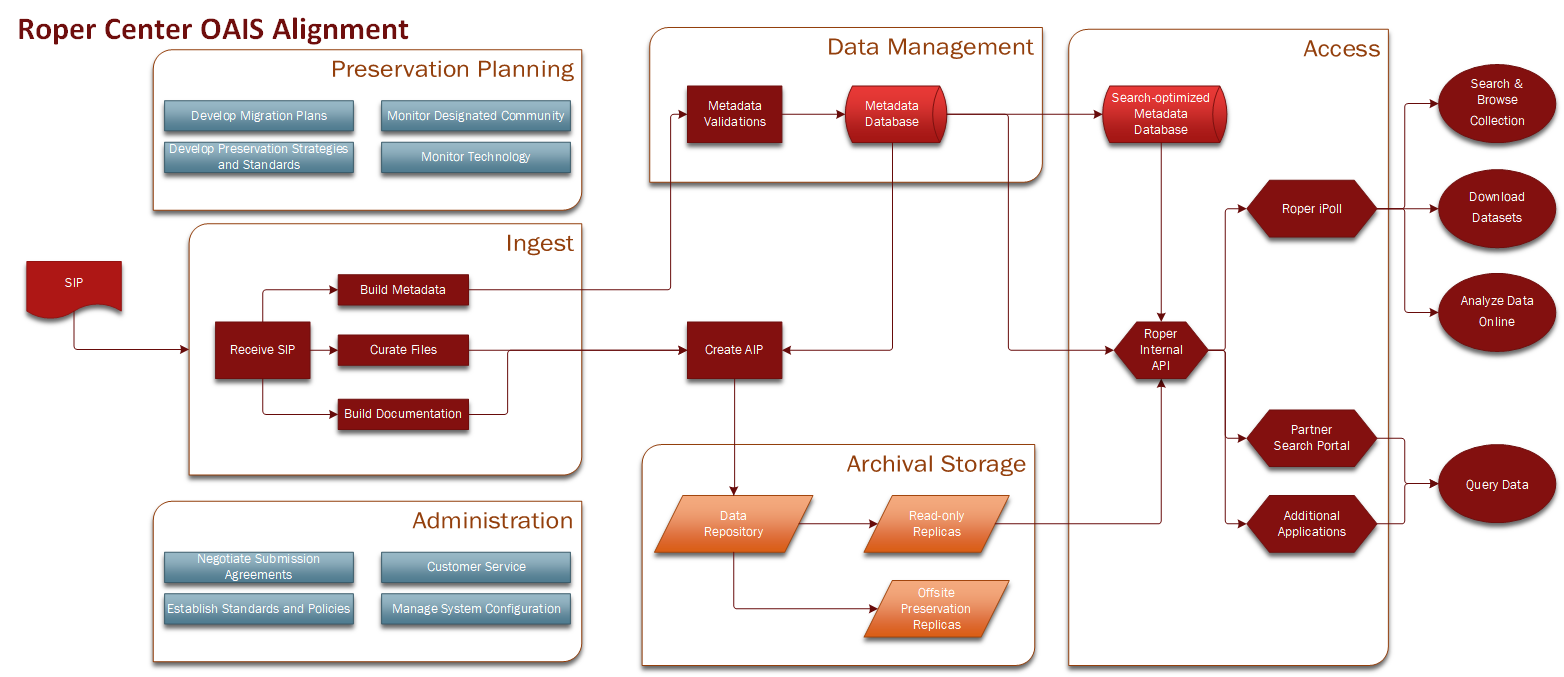
The Roper Center’s processing and preservation practices are based on the Reference Model for an Open Archival Information System (OAIS) produced by the NASA Consultative Committee for Space Systems [1]. The OAIS Reference Model is an ISO (International Organization for Standardization) standard that provides a framework for managing and preserving digital objects in archival repositories. The Roper Center’s processing functions align with the OAIS functional model:
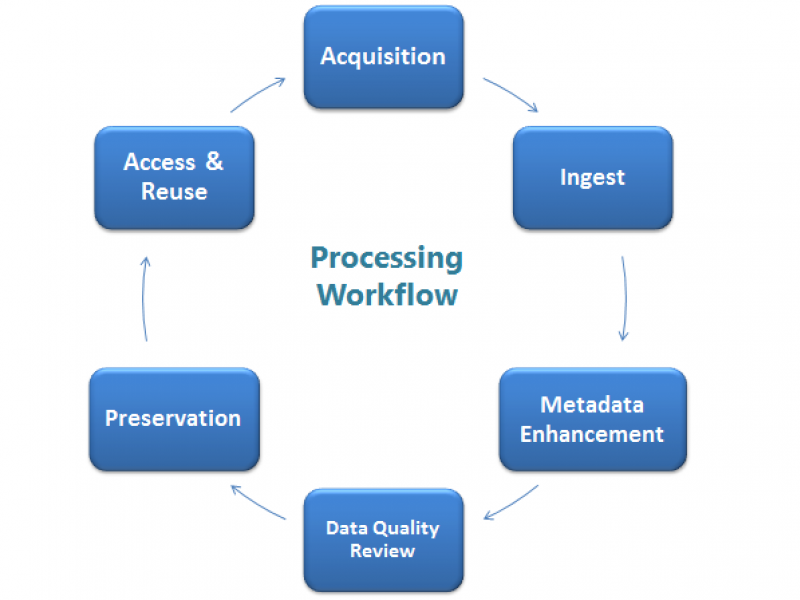
Processing Workflow
The Roper Center processing workflow is a continuous cycle of six different phases. During each phase, staff members use their extensive training and expertise in data management, metadata standards, and archival practices to ensure advancement of the Roper Center’s mission. For more details, view this Detailed Processing Workflow Diagram.
What is data archiving?
“Data archiving” describes a broad range of processes undertaken to ensure that data can be used and understood by researchers now and into the future. Data archiving includes preservation activities, like protection against file degradation, migration of files into updated formats, maintenance of duplicate copies, and digitization of supporting documentation. But data archiving also means data cleaning, respondent de-identification, and metadata collection on studies and files in order to build discovery and analysis tools that help researchers find and understand the data. The Roper Center’s data archiving process meets best practices of the data archives community and has been certified by the CoreTrustSeal.
![]() .
.
What does the Roper’s data archiving process look like?
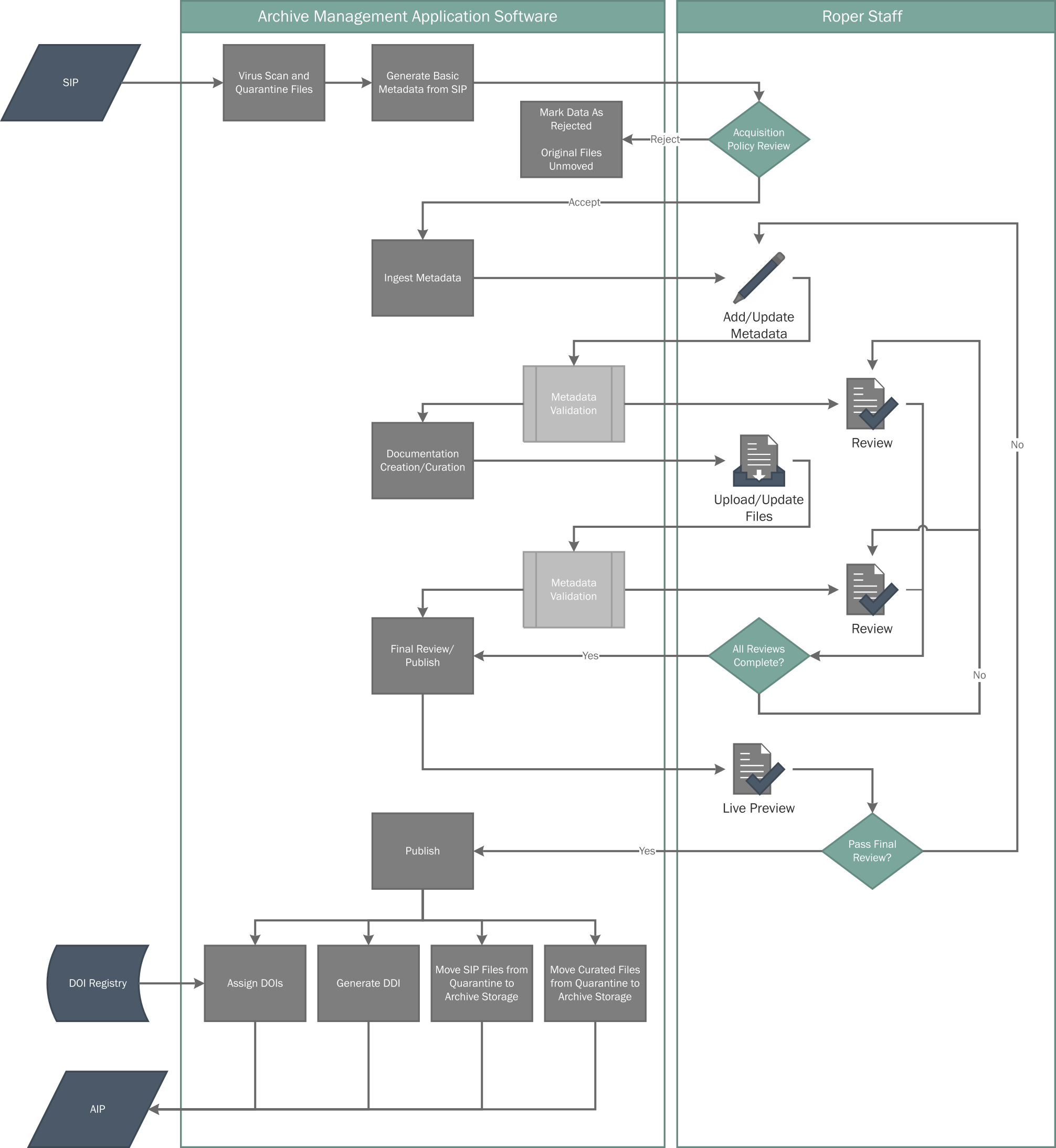
When a new submission is received by the Roper Center from one of its approved data providers, the dataset first undergoes a series of checks, including a file virus scan, a review of the contents of the submission to ensure that all required items are included, and an acquisitions policy review to determine that the study meets Roper Center’s standards for methodology, practices, and disclosure.
Then the dataset is reviewed in detail. Our data processors verify that each item in the questionnaire is related to a variable in the dataset, that skip patterns in the questionnaire match missing data patterns in the dataset, that there are no duplicate variable names, and that no values fall out of range. Sometimes we have to ask data providers for more information to ensure that researchers will be able to use the dataset with a full understanding of what each variable means.
Because Roper datasets are published for use by a broad range of researchers, one of the most important parts of the archival process is ensuring that both direct and indirect identifiers of respondents have been removed. This procedure involves deleting demographic variables, like geographical codes for small areas that could be used in conjunction with other demographic information to determine the identity of a survey respondent.
Once the dataset review has been completed, file formats for the submitted data and documentation are converted to archival formats for preservation, while additional formats are generated for ease of use by researchers.
The next step is the entry of detailed metadata – the descriptive information about each survey that serves as the engine for Roper search and discovery tools. Metadata is collected about each survey document, the coverage of the survey, methods of data collection, the organizations involved in the development and fielding of the survey, funding sources, and topics of survey questions. Finally, the new study is published to the website, where Roper users can use our search tools to find the data and download the archival package of materials.
What about the question database?
Our archive of questions is built from public poll releases, not from datasets. Roper compiles topline statistics as they are published, allowing researchers to keep abreast of the most recent U.S. polling results across organizations. Polling organizations share their releases with the Center as they are made public. The results are formatted to meet standard conventions, then entered manually in the database, along with metadata information about the survey sponsorship and methodology. The database entries undergo three rounds of proofing and revision to ensure accuracy. Then the results are published. When datasets from U.S. polls with results iPoll arrive at the Center, they go through the same archival process as other datasets submitted to the Center, with one addition: the variables that were used to generate iPoll questions are identified and linked to the iPoll entries, and standard demographic variables are recoded to build the crosstab functionality.
An ongoing process
Data archiving does not end with publication, but rather is a constantly evolving process. Older surveys require file format conversion as new statistical software packages supplant older versions. In some cases, researchers may use the data in the archive to develop new datasets, which then can in turn be archived at the Center. As research interests change, users look for different information about studies of the past. Metadata fields may be added to capture additional information about each study, and older database records updated by reviewing existing documentation for more information. The Roper Center is committed to not just preservation, but robust ongoing curation of the data in its archive.
Learn more about the technical details of Roper’s data curation process.
| Phases | Example practices and procedures |
|---|---|
| Acquisition |
|
| Ingest |
|
| Metadata Enhancement |
|
| Data Quality Review |
|
| Preservation & Storage |
|
| Access & Reuse |
|
[1] CCSDS, Reference Model for an Open Archival Information System (OAIS): Recommended Practice



{kind=link}